Nothing boosts the
prospects of page hits on a blog – or funding of a grant proposal – like the
phrase “big data.” Why are we enamored with “big data”? It’s not the magic
bullet of management or policy: It’s made money for a few companies, but has
backfired bigtime in the arenas of national security (NSA surveillance
scandals) and social media (Facebook manipulating your emotions without your
informed consent; OKCupid doing basically the same thing).
Online stores serve you “recommendations” that couldn’t interest you less.
The failures don’t belie
the potential of big data; they’re just people failures and symptoms of the
immaturity of the field. But that’s the point: As Jon Low says, “Data without
context, interpretation and courage is simply a bunch of numbers.” Managers have to provide the context and motive
for deep analytics. That will remain true even when “data science” matures. (Or
until the Kurzweil/Vinge singularity, whichever comes first!)
At Market Research Corporation
of America – my employer in the 1980s – we were proud of having the “world’s
largest private database.” It was laughably small by today’s standards. But we
learned a lot about what it means to mine what then passed for big data, and
the home truths still apply.
Those truths have to do
with deciding whether something is true or merely useful, the role of human
creativity in posing questions, the speed of analytics versus the speed of
decision-making, and the role of theory in data mining.
Here are guidelines for
thinking about big data.
Big data: The end of
Fisherian hypothesis testing?
Since the agricultural
experiments of the early 20th century, scientists have formed
hypotheses from empirical observation (or from detecting gaps in theory), and
tested the hypotheses on data gathered for that express purpose. That is,
humans generated the hypotheses, and the hypotheses were tied up with human
meaning and intent. Each hypothesis was tested on an independent data set. This
was the classical statistical method, often called Fisherian in deference to
R.A. Fisher, its originator.
Sometimes curves were
fitted on a subset of the data, with some data points “held out” for a
confirmatory test. This foreshadowed some techniques of big data, as we’ll see.
Later in the century,
statisticians (notably J.W. Tukey) argued for “exploratory data analysis.” This
work leveraged the era’s increased computational power. It meant that empirical
hypotheses could be suggested by patterns in a data set rather than from
observation of the material-energetic world. Nonetheless, hypotheses were
articulated by human analysts, and tested on new data sets, never the same data
set. Tukey’s work foreshadowed and inspired the data visualization that is a
standard feature of today’s age of big data.
Generating hypotheses
automatically
A 1976 paper of mine showed
the possibility of machine-generated hypotheses. It was reamed by reviewers,
and I had to tone it down in order to get it published. I shared the referees’
revulsion for the idea, but was trying only to show that it was technically
possible and had a sound theoretical grounding in Shannon-Kullback information
theory.
Why
the disgust over machine-generated hypotheses? Campbell (1982) noted the rise
of statistical inference followed the then-new notions of thermodynamics and
irreversibility, and the later use of these notions in statistical mechanics:
Statistics belongs ...to
the domain of the organic, to fluctuating life, to Destiny and Incident and not
to the worlds of laws and timeless causality ... As everyone knows, statistics
serves above all to characterize political and economic, that is, historical
developments. In the ‘classical' mechanics of Galileo and Newton there would
have been no room for them. And if now, suddenly, the contents of that field
are supposed to be understood and understandable only statistically and under
the aspect of probability ...what does it mean? It means that the object of
understanding is ourselves.
Perhaps Campbell overstated
the case. Let’s remember, though: The fate of Schrödinger’s cat remains
undetermined until a person opens its
box.
Theory – DYANA
The data business has small
profit margins. To exercise any pricing power, you need to deliver useful
analysis and advice to clients.
This was our challenge at
MRCA: How to make sense of all that data? We needed a framework for comprehending
the data. We found it in the work of marketing scholar Andrew Ehrenberg, who
claimed that the negative binomial distribution was the best fit for
frequency-of-purchase patterns. Well, whether it was NBD or not, we found we
could build a decision support system around software that generated purchase
frequency distributions from our data, filtered by demographic and behavioral
parameters. We called it DYANA, for dynamic analysis. Quaint, eh?
Knowing how many US
households bought an item 0,1, 2, etc. times let us quickly determine average
frequency, market penetration, and repeat-buying rates. Drilling down, we could
see, for example, how many similar items from manufacturers other than our
client were bought by light buyers of our client’s goods. And so on. It worked.
Clients loved it.
This led to the insight
that theory is a necessary overlay for making sense of big data.
Of course when big data are
used for speed and not for knowledge – for example, arbitraging a financial
position – it’s a different matter, in fact not science at all. Nobody wants it
to ‘make sense’; they just want it to be profitable.
Volume, velocity, and
variety.
Today’s big data are
characterized by these three Vs. Volumes and volumes of data. Measuring
instantaneous changes in markets, metabolisms, and what have you, and delivered
to your PC or handheld in milliseconds, from naturally refrigerated server
farms in Finland and under the Swiss Alps.
Back in the day, we celebrated
DYANA’s ability to deliver results to clients in three days instead of six
weeks. We never envisioned millisecond delivery. (As my current métier is technology
forecasting, I feel embarrassed to admit this.) The data were stored on
reel-to-reel magnetic tapes, as in the photo, with speed limited by the ability
of the data librarian to find and mount the right tape.

It was a conventional
relational database of ASCII characters. ‘Variety’ in modern big data means a
mix of character, photo, drawing, video and sound files. Inconceivable back
then!
And yet, it fit the
managerial decision cycles of our clients, companies like Coca-Cola, Nabisco,
Procter&Gamble, and General Mills. When our competitors began to use
supermarket scanners to collect greater masses of data, we didn’t worry because
they did not have the skill to process it. Our complacency was misconceived:
They soon figured out how to get actionable information out of that mass of
data. Our customer base dwindled, as clients adapted their marketing decision
making to accommodate more and faster data.
Fishing in the data
Raise a glass to the
curiosity of PhD students! They want to answer so many questions, and can
afford so little data. As a result, they tend to test too many hypotheses on a
single data set. Let’s see why this is risky.
In statistical inference
you may reject (or not) a hypothesis at, say, a 90% level. This means (and this
meaning is often forgotten) that if you repeat the same experiment on 100
independent random samples of the same size, you will reach the same conclusion
about 90 times. You will reach the opposite conclusion about 10 times!
By the same token, if you
test multiple hypotheses on the same data set, you increase the chances that
you will get a false positive or false negative on at least one of them. This
practice is called fishing in the data. The reason for the moniker (which has
no connection to Sir Ronald Fisher, so punsters please control yourselves) is
that if you test enough ideas on a single data set, you’re likely to get at
least one positive result – even if that result is spurious.
This too has implications
for big data practitioners. One is that tests should be done either on
different large subsets of the big database, or if that is impossible, the acceptance
region (significance level) should be tightened for each successive hypothesis
that is tested on the entire database.
Another is that money can
be made even on “spurious” results.
There is no ‘data science’ –
only science.
It’s
human nature to get excited when one of the components of scientific progress
takes a giant leap, and to focus on it to the exclusion of the others.
Understandable, but short-sighted; we should be looking ahead to its
implications for the other parts of scientific advance. In 1993 Learner and I
wrote:
| "Science progresses when any one of its four components – theory, data, methodology and problems – advances by building on the current state of the other three. In a continuing game of leapfrog, any one of the four sectors may experience a breakthrough (at a moment when the others are less active), leaping to the forefront and often spurring support activity and progress among the other three. A new theory may spur researchers to gather data to test it, and the possibility of commercial development [or public good] may make the expense of such data collection worth undertaking.... For instance, the germ theory of disease could not emerge until the microscope (a methodological advance) revealed a new body of previously unobservable data." |
 |
![]()

A
Leapfrog Model of Scientific Advance
Today, large data sets are made possible by cheaper storage and processing. Storage
and processing are methodologies. The
data sets give rise to still more methodologies (Python and R languages, new
visualization techniques) that may or may not lead to new theories, but in any event are believed to be relevant to problems in marketing, medicine, and environment.
Thus, there is no “data
science.” There is only science. Data – and the ways we process it – are just
two of its parts. Advances in data (data collection, data definition, data
storage, data ontology, etc.) will be followed by advances in analytic methods,
new theories (these are already starting to emerge in medicine and
scientometrics, to name two areas), the solution of old problems, and the
uncovering of new problems. Let’s remember the lesson from the market research
firm in the 1980s, and not focus unduly only on the data.
Managerial
significance vs. statistical significance
This
is a key concept for gaining perspective on big data. To a statistician, the
difference between the two kinds of significance lies only in the acceptance
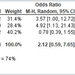
region, or “p-value.” Three examples will illustrate.
1. Your data warehouse’s neural net program detects a slightly
greater preference for red widgets among buyers in the western part of the
country, and for blue widgets in the east. The difference is not statistically significant (at the
usual 95% level) and may not be a lasting effect, but it does involve several
thousand consumers. At no cost,
the neural net triggers another program that routes more red widgets to stores
in the west. Revenue is realized
that might otherwise have been left on the table. The cost-effectiveness
profile of this action means it was managerially significant but not statistically significant. A
statistician might insist on at least a 90% test; managerially, a 50% test
would justify action.
2. Based on your solid research conclusions, you recommend a
certain government action. It is
not certain that the desired benefit would exceed the considerable cost, and
the program would compete with other worthy government budget priorities. Your
research is sound at the 95% level, but the government would, effectively,
require a 99.5% level to move this project up the priority list. It is statistically significant but not managerially significant.
3. A 2005 study shows conclusively that the ‘Mediterranean’
diet is superior to the usually prescribed low-fat diet for decreasing blood
cholesterol. Food producers, consumers, physicians, pharma companies, and
health care payers all have different and possibly conflicting interests in this
matter. There is no coordinating mechanism for resolving these conflicts. In
other words, the chance that the research will change the way people eat is
about nil. The research is statistically significant but not managerially
significant at this time.
I did
say we can make money from spurious results. To the statistician, ‘spurious’ can
mean incorrect. It can also mean not reliable, not replicable. In markets that
change in fractions of a second, like securities trading or, to a less extreme
extent, example #1 above, any arbitrage opportunity may be ephemeral. That is,
it can change so fast that replication is not only impossible but meaningless.
This means the p-value argument that opened this section is also meaningless in
such a case: We cannot test the opportunity on a hold-out sample.
But
go ahead and sell that stock, or ship those red widgets, and do it quick. Put
some of the proceeds in the bank, and buy me a beer with the rest.
That
particular gap in the market lasted only microseconds. It resulted in no
lasting knowledge or general principles, so statisticians have nothing to say
about it. But it was useful for us, for a short time.
The singularity
You know the story – the
day will come when computers are smarter than people, and we’ll all take orders
from machines. I’m going to express an opinion, since we’re on the subject.
That is that it won’t be much different from now. People in many occupations
already have good, rational, non-embarrassing reasons for doing what a computer
says. I’ve written about them here.
Other people, especially in
service professions, blindly obey computers even when they shouldn’t. We’ve all
had occasion to ask such a person for a perfectly reasonable resolution to our
problem, only to hear them tap keys and say, “The system won’t let me do that.”
Don’t you want to leap over the counter, grab him/her by the lapels and shout,
“I DON’T CARE ABOUT YOUR ‘SYSTEM.’ YOU
CAN DO THIS FOR ME.”
Another anticipated feature
of the singularity is the convergence of the virtual world and the meat world.
This too is here already. Every day I meet people who are aware (and curious)
about what’s going on around them, and people who are not. The latter are stuck
inside their heads, where they must be processing some kind of model (of
whatever level of imperfectness) of the world they live in. That is, they are
living in a virtual world of their own devising, without a computer, and yet somehow
have managed to keep their bodies alive in the external world.
The singularity will depend
on big data. However, I expect no big surprises when it arrives, and no big
changes.
Retailer John Wanamaker said, “Half the money I spend on advertising is wasted. The trouble is I
don't know which half.” Countless marketing managers have echoed the sentiment. Big data
will eventually ease, if not solve, the problem. Meanwhile, target marketing resembles what someone else said of
communism and Christianity: They both sound like good ideas, but no one’s ever been
seen actually practicing either of them.
Refs
J.
Campbell, Grammatical Man: Information, Entropy, Language, and Life. Simon&Schuster, New York (1982).
L.
Delcambre, F. Phillips and M. Weaver, “Knowledge Management: A Re-Assessment
and Case.” Knowledge, Technology&Policy, 17:3, 2005.
D.B.
Learner and F.Y. Phillips, "Method and Progress in Management
Science." Socio-Economic Planning Sciences, Vol. 27, No. 1, pp. 9-24, 1993.
J.
Low, “Despite Disruption, Data and Deadlines, Managers Still Need to Decide.”
The Lowdown, July 31, 2014. http://www.thelowdownblog.com/2014/07/despite-disruption-data-and-deadlines.html?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+TheLow-down+%28The+Low-Down%29
S.
Noonoo, “Southern Methodist U Debuts Online Grad Program in Data Science.” Campus
Technology, 07/31/14. http://campustechnology.com/articles/2014/07/31/southern-methodist-u-de…
F.
Phillips, G.M. White and K.E. Haynes, "Extremal Approaches to Estimating
Spatial Interaction". Geographical
Analysis, Vol. 8, April, 1976, 185-200.
F.
Phillips, "Advanced DSS Design in Consumer and Marketing
Research". DSS'85: Fifth International Conference on
Decision Support Systems, 1985. Anthologized in R. Sprague and H.
Watson, eds., Decision Support Systems: Putting Theory into Practice. Prentice-Hall,
1986.